
marimo as a Jupyter alternative
marimo feels like a reactive notebook, but is stored as git-friendly Python that can be pushed to production or easily deployed as an app. It’s the Jupyter alternative you’ve been looking for.

marimo is an open-source programming environment that blends the best parts of interactive computing with the rigor of traditional software development. Unlike Jupyter notebooks, marimo notebooks are reproducible, execute reactively, have interactive elements built-in (no callbacks!), stored as pure Python, versionable with Git, deployable as web apps, and executable as scripts. The result is an entirely new kind of notebook. It’s the Jupyter alternative you’ve been looking for.
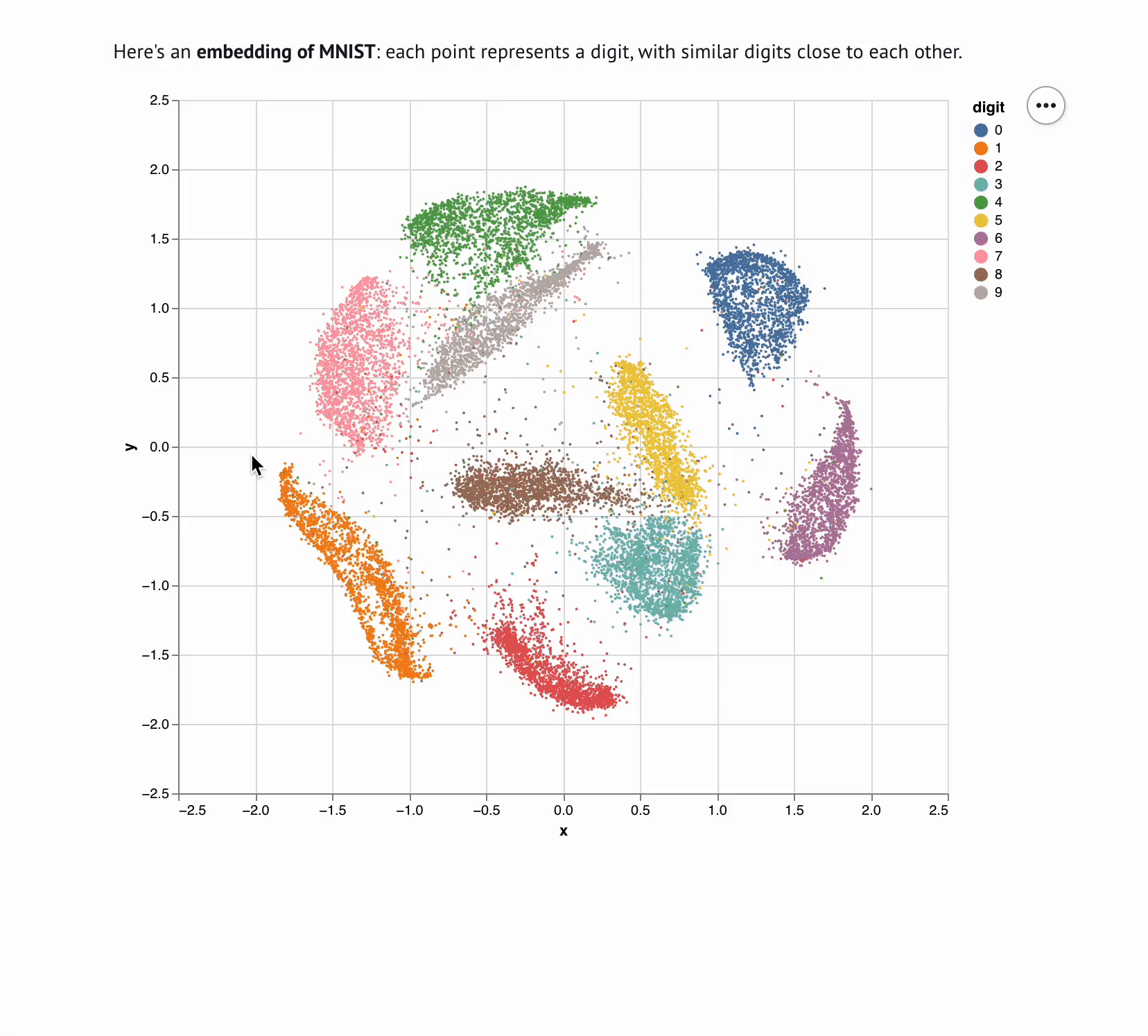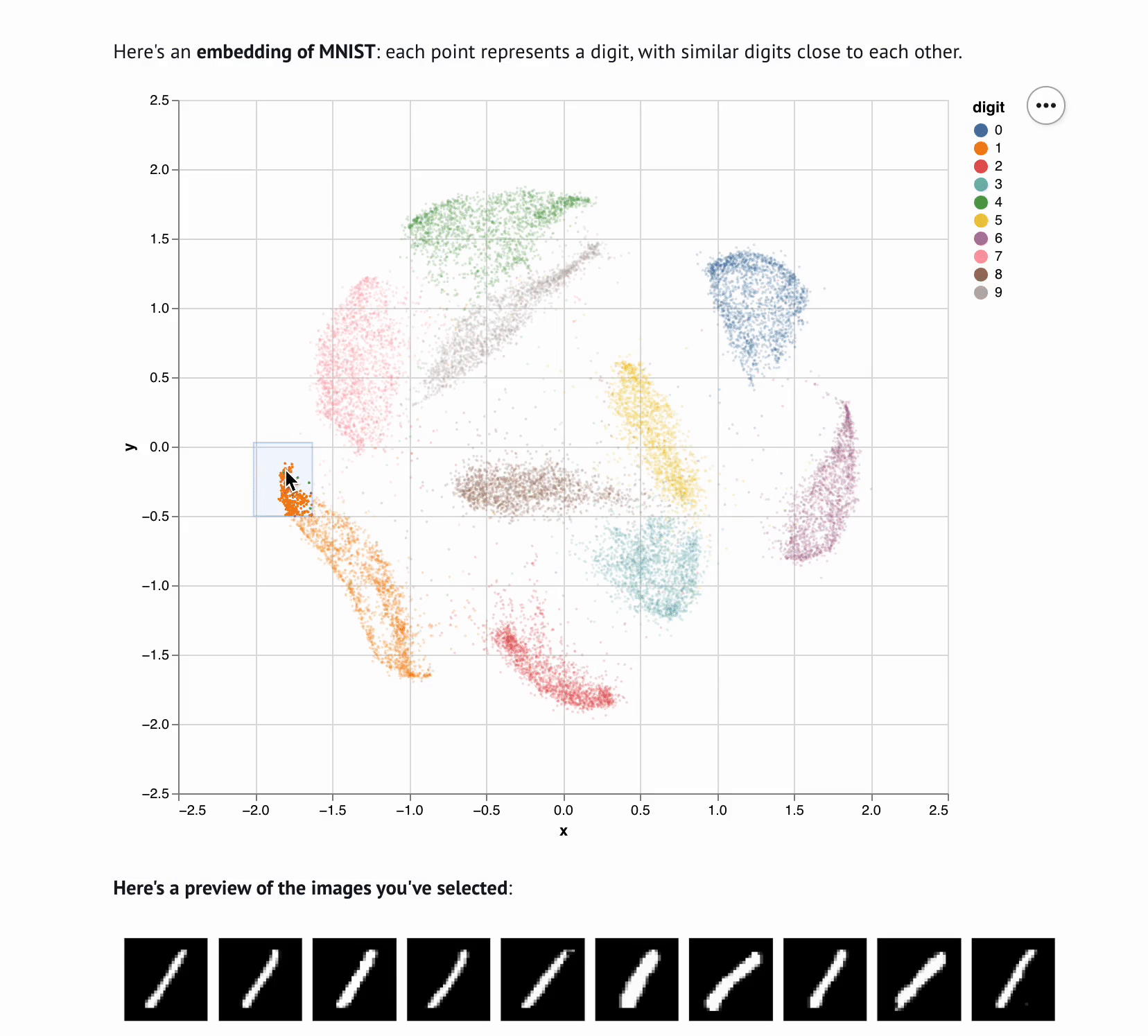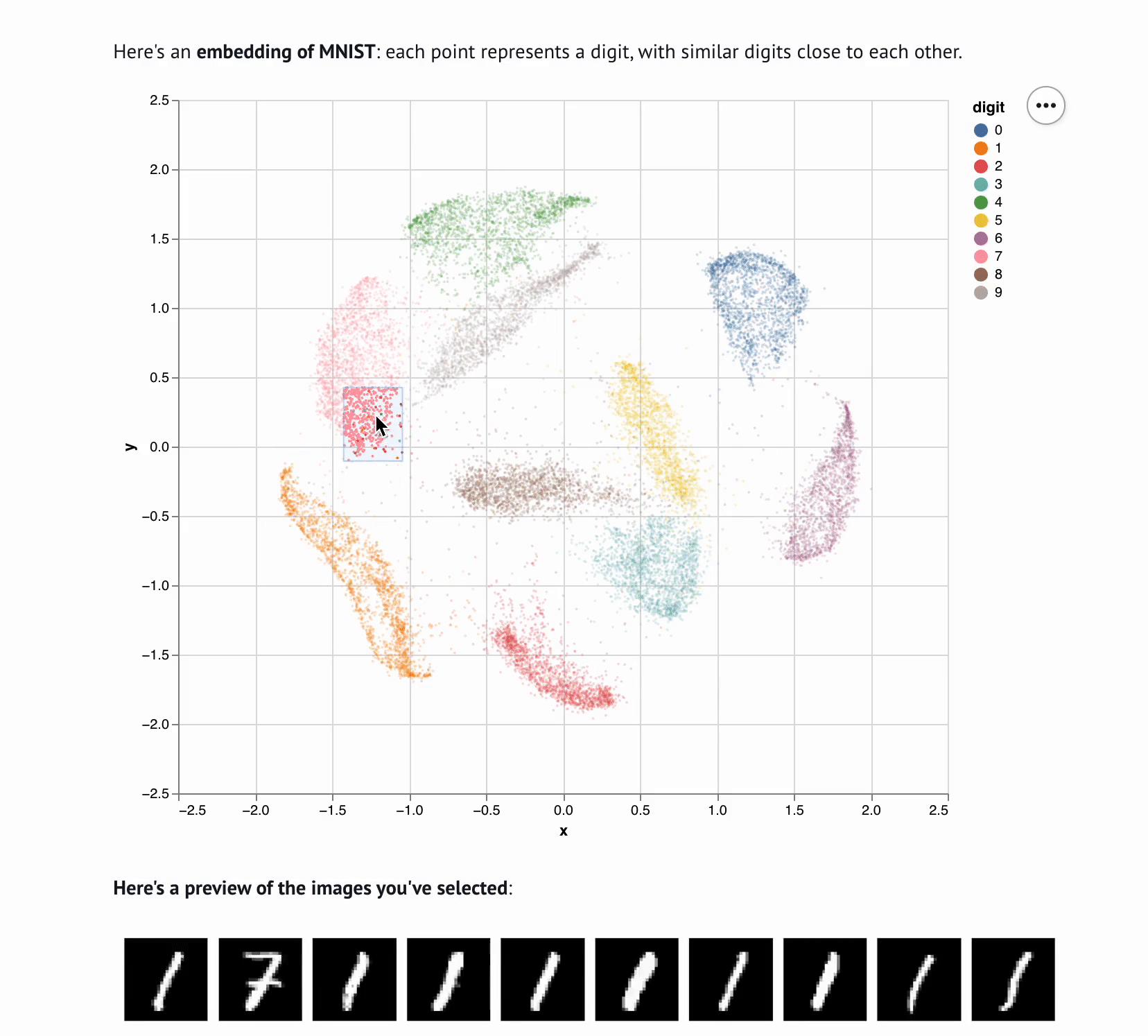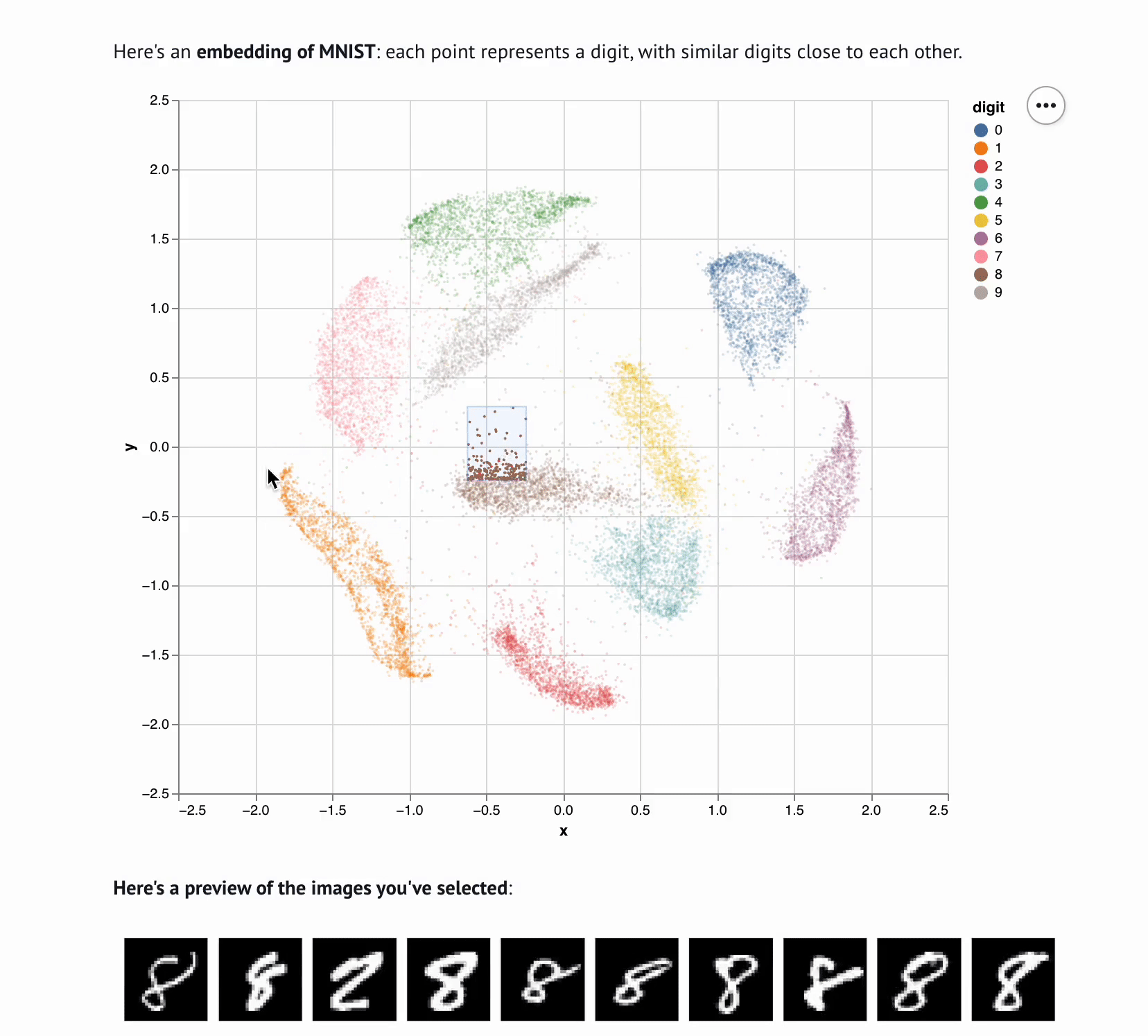
marimo notebooks bring data to life with reactive execution and interactive elements.
Computational notebooks for Python
The origins of the first mainstream notebook for Python, Jupyter, can be traced back to the IPython project. IPython is a read-eval-print loop (REPL) or scratchpad for Python that runs in the terminal. It let you run code line by line, mutating memory and letting you inspect intermediate outputs like plots. Initially developed in 2001 as an academic project, IPython eventually became the basis for the Jupyter notebook, which can be thought of as “IPython in the browser”, with visual outputs saved alongside the code you just ran. Like IPython, Jupyter was also an academic project, released in 2014.
Unlike traditional Python scripts, which run from start to finish without human intervention, Jupyter allowed developers to write code incrementally, using intermediate execution results as feedback for what to author next. This was so valuable and unprecedented for Python developers that a lot of important work started to happen in notebooks — research, large scale experimentation, model training, data engineering, and more.
Despite being used for critical work, Jupyter remained a REPL. It was never designed with reproducibility and reusability in mind, two properties that are essential for the kind of critical workloads that people began driving through notebooks. The impedance mismatch of what Jupyter fundamentally was — a scratchpad — and what people used Jupyter for — critical research, experimentation, model training, and data engineering — led to an enormous number of problems, and is what fundamentally motivated us to make something better in marimo.
Challenges with Jupyter
Just like a REPL, Jupyter lets developers execute cells one at a time, in any order, with each cell modifying a mutable workspace (i.e., the variables in memory). This hidden state is a huge problem for reproducibility. It’s why when you receive a notebook from a colleague and try to run it from top to bottom, the notebook often breaks.
Ultimately, hidden state leads to hidden bugs (over 75% of Jupyter notebooks on GitHub don’t run, 96% of notebooks don’t reproduce), the JSON file format makes Jupyter hard to use in Python codebases, they’re difficult to use with agents like Claude Code because file format is not plaintext, and the final documents lacked interactivity. While Jupyter notebooks are widely used for AI/ML development, STEM, and data engineering, now more than ever, there’s growing consensus that this kind of work shouldn’t be done in error-prone scratchpads.
How marimo fixes notebooks
Reactive execution model
Unlike Jupyter’s top-to-bottom execution model, marimo uses reactive execution. When a cell is run, marimo automatically runs all cells that depend on the variables it defines. Code and outputs are kept in sync automatically, which eliminates hidden state and rapidly accelerates data exploration when combined with interactive elements. (For expensive notebooks, marimo offers an option to mark outputs as stale instead of autorunning.)
Interactive elements and seamless web app deployment
With marimo, every notebook is instantly deployable as an interactive web app — no extra frameworks, translation, or boilerplate required. Interactive elements like sliders, dropdowns, tables, and plots can be created programmatically with just a single line of code, letting users turn notebooks into shareable dashboards, reports, or powerful internal tools in minutes. (Because marimo is fully compatible with the anywidget ecosystem, users can also embed custom interactive components, like 3D visualizations and bespoke controls, directly into the notebook.)
UI elements are bound to Python variables, and thanks to reactive execution, interacting with a UI element automatically triggers execution of downstream cells with the element’s new value; this makes them far easier to use than Jupyter’s ipywidgets. What once required Streamlit, Gradio, or Plotly Dash is now offered natively inside in a notebook, with no extra effort.
AI Agents
For many of the reasons listed above, Jupyter notebooks are ill-suited for agentic coding tools. marimo, on the other hand, is the first AI-native notebook environment, built to work with tools like Claude Code. This is for a few reasons:
- File format. By default Jupyter notebooks are stored as JSON with base64-encoded outputs, not Python. But LLMs work best when generating code, and marimo is stored as Python, not JSON, empowering agents to do their best work.
- Reproducibility. Jupyter notebooks, as well as their commercial skins, suffer from a reproducibility crisis: they are not well-formed programs but instead have hidden state and hidden bugs. This trips up not only humans but also agents. In contrast, marimo notebooks are reproducible Python programs with well-defined execution semantics. Deterministic state means agents can rely on consistent behavior.
- Composability and programmability. marimo is code-first, letting humans and agents alike create powerful UIs with just Python.
- Introspection. Agents work best when they can test what they’ve done. marimo notebooks are Python programs, so agents can run them and inspect outputs; the same is not true for Jupyter notebooks.
marimo makes it possible for humans and AI agents to collaborate seamlessly in the same environment, something Jupyter notebooks were never designed to support. If you’re choosing tooling, see why marimo is the best AI agent setup for Jupyter notebooks.
Version control with Git
One of the biggest pain points with Jupyter notebooks is version control. Rerunning a single cell in Jupyter will always cause a change in a .ipynb file because the metadata needs to update to reflect the order in which the cells ran. JSON files with embedded output and metadata create noisy diffs that make it nearly impossible to track meaningful changes. By using Python files, marimo effectively removes this problem. When you need to share your results, marimo still lets you export notebooks to HTML or IPYNB, and even lets you share notebooks as interactive web apps.
The clean file format also means you can use standard git hooks, pre-commit tools, and automated code quality checks on your notebooks without additional tooling or configuration.
marimo notebooks as production-ready .py files
Storing notebooks as pure Python files has many benefits, mainly because it’s much easier to enjoy all the progress and benefits from the Python ecosystem:
- run notebooks from the command-line as normal Python scripts;
- productionize notebooks as parameterized and testable pipelines, workflows, endpoints or reusable libraries;
- encapsulate Python dependencies as metadata in the notebook file itself;
- use formatting tools like ruff and black on notebook files;
- import Python functions from a marimo notebook and re-use them across your Python project;
- test notebooks with pytest.
This file format choice eliminates the friction that data, ML and AI teams often experience when transitioning between notebook and script environments.
The future of notebooks
For the past two decades, Python notebooks have been a scratchpad; a place to experiment, visualize, and iterate. But they were used as more than that, leading to all kinds of problems, and dictating how an entire generation of machine learning and data teams have worked.
But the world has changed. Teams now expect and require their notebooks to work like software; reproducible, collaborative, and deployable. Thanks to marimo, the boundary between “notebook”, “data app”, and Python script is rapidly disappearing. Data, ML and AI workflows need reliability, reactivity, and integration with modern infrastructure.
The next generation of Python notebooks won’t just be a static scratchpad for visualizing code and outputs, it’ll be a reactive environment that eliminates hidden state, encodes cross-cell dependencies, and serves as the single source of truth for data and ML teams. In this new paradigm, every notebook will be a reproducible software artifact that can be reused in many different ways.
This is the world we’re building for at marimo. It’s not an incremental improvement or skin on Jupyter; it’s a reimagination of what a notebook can be when designed for the modern stack.
Learn more about how companies like Sumble, DNB, Bunkerhill and others are already living this future with marimo.
How to use marimo
marimo is entirely free and open source. Just pip install marimo or uv add marimo to get started.
marimo also offers a free, cloud-hosted notebook; molab. Check out our gallery for inspiration and examples from our community.