
Reinventing notebooks as reusable Python programs

marimo is free and open source, available on GitHub. This blog post is also accompanied by a YouTube video.
In a previous post, on lessons learned redesigning the Python notebook, we wrote:
A lot of important work happens in notebooks — research, large scale experimentation, data engineering, and more. But this kind of work should be treated as Python software, and it shouldn’t be done in error-prone JSON scratchpads.
In that post we described design decisions that allowed us to create a new kind of notebook (marimo), one that blended the best parts of interactive computing with the maintainability, reusability, and interoperability of software. Part of our solution was to represent notebooks as Python programs — not just as flat scripts, but as reusable modules.
In this post, we dive deep into our representation of notebooks as Python files — showing how our file format makes notebooks versionable with Git, importable as modules, testable with pytest, executable as scripts, and much, more, while still being compatible with other languages like SQL and Markdown. We also discussing how we design around tradeoffs, such as keeping a record of visual outputs.
Contents
The status quo is not working
AI developers, data engineers, data scientists, and researchers do a lot of their work in Python notebooks like Jupyter. We know this from first-hand experience; we’ve worked as engineers at Google Brain and Palantir, and lived in notebooks, for better or worse, during PhDs at Stanford and Johns Hopkins.
Traditional notebooks’ usefulness is severely limited by the JSON-based
ipynb file format (among other things).
This file format combines code and outputs in what Pydantic creator Samuel
Colvin calls a “horrid blob”, and is
directly responsible for the following sad state of affairs:
- small edits to code yield enormous Git diffs;
- code is copy-pasted across notebooks, instead of reused;
- magic commands limit the portability of notebook code;
- logic that would be useful as a script or library gets thrown away;
- logic that should be tested almost never is.
What about Jupytext or Databricks source notebooks?
While it’s true that you can get cleaner diffs by using Jupytext (if you’re sufficiently motivated) or Databricks source notebooks (if you’re a paying customer), naively storing notebooks as flat Python scripts like these tools do won’t solve the other problems enumerated above. In particular, importing a Jupytext-processed or Databricks source-format notebook as a module will also run all its cells — a potentially very expensive side-effect if all you wanted was to import a function or class.
What about nbdev?
nbdev is a framework that lets developers “write, test, document, and distribute software packages and technical articles” using Jupyter notebooks, a goal that we consider orthogonal to our goal of making a new kind of Python notebook that is a simple software artifact, just like any other Python file. We are not interested in replacing traditional software development with notebooks.
When working with Jupyter, too often you end up with directories strewn with spaghetti-code notebooks, counting up to Untitled12.ipynb or higher. You the notebook author don’t know what’s in these notebooks, you don’t understand their Git history, you don’t know what packages were used in each notebook, you haven’t tested anything because how do you even test notebooks, and you’re unsure if you — let alone your colleagues — will be able to run them in the future.

Despite these problems (and others — by one study, less than four percent of Jupyter notebooks on GitHub are reproducible), people continue using traditional notebooks for production tasks like pipelines (e.g., Databricks workflows), as well as areas where reproducibility is paramount, like AI development and science.
Why? Because, until recently, Jupyter notebooks were the only programming environment that let you see your data while you worked on it. Interactivity is so crucial to data work that hundreds of thousands of data professionals decided the trade-offs were worth it.
Instead of accepting this sad state of affairs, or trying to work around it with clunky extensions or complicated frameworks, we decided it was worth it to reinvent notebooks as regular Python programs — we wanted to make something that just worked. It was from this belief that the marimo notebook was born.
Python, not JSON: a new plaintext file format
marimo stores notebooks as plaintext Python files (e.g. notebook.py) with the
following properties:
- Git-friendly: small code change => small diff
- easy for both humans and computers to read
- importable as a Python module, without executing notebook cells
- executable as a Python script
- editable with a text editor
After a lot of careful consideration, we landed on files that look like this:
import marimo
__generated_with = "0.11.17"
app = marimo.App()
@app.cell
def defines_x() -> int:
x = 0
return x,
@app.cell
def defines_y(x):
y = x + 1
y
return y,
@app.function
def add_one(arg):
return arg + 1
@app.cell
def computes_z(x, y):
z = add_one(x + y)
z
return z,
if __name__ == "__main__":
app.run()This file format encodes how data flows across the notebook: as we explained in our previous post, marimo represents notebooks as dataflow graphs to improve reproducibility (eliminating hidden state) and enable seamless interactivity with UI elements.
Anatomy of a notebook file
marimo automatically generates notebook files on save from the marimo editor, but developers can also create or edit these files in their text editor of choice (ours are neovim and Cursor).
Header. The notebook file starts with a header that imports marimo, notes
the version of marimo that created the file, and instantiates an App object
to which cells are added.
Cells. Cells are stored in notebook presentation order. Each cell is
serialized as a function that accepts its variable references and return its
definitions; cells are added to the notebook via the app.cell decorator.
Users can optionally name their cells, which become the names of the decorated
functions.
This serialization strategy departs from Jupytext-style (or Databricks-style) flat scripts, which demarcate cells with comments instead of wrapping them in functions. Importing Jupytext or Databricks notebook files runs all their cells, which is expensive and almost never what you want. In contrast, in our file format, cells are not executed on import because they are wrapped in functions.
Functions and classes. This part of our notebook specification is slated
for release in version 0.12.0. Cells that define top-level functions or
classes are serialized directly in the file, so they can be reused by other
Python modules (from my_notebook import my_function). An optional top-level
setup cell, not shown here, can make symbols available to these functions, such
as imported modules and constants.
Footer. An if __name__ == "__main__" guard protects a call to app.run(),
which executes the notebook’s cells in a topologically sorted order.
Examples
Our simple file format makes it possible to treat notebooks like any other Python program. Here are some examples of what our file format enables:
Version with Git
Small changes to notebook code are guaranteed to make small localized changes to the notebook file, yielding easy-to-read Git diffs. For example, consider a one character change, modifying
plt.plot(x, x**2)to
plt.plot(x, x**3).marimo notebook diff. Here’s the Git diff for a marimo notebook file:
@app.cell
def _(plt, x):
- plt.plot(x, x**2)
+ plt.plot(x, x**3)
returnIt corresponds exactly to the code change, with the notebook file changed in just one place.
Jupyter notebook diff. In contrast, because ipynb files stores base64-encoded blobs of outputs, the diff for the equivalent Jupyter notebook contains 42,571 characters. Moreover, the notebook contains many changes unrelated to the actual single character code change. Here is an abbreviated version of the diff, with truncated blobs.
Expand to see the diff (it’s long!)
diff --git a/Untitled.ipynb b/Untitled.ipynb
index 0a76b5f..74b0c08 100644
--- a/Untitled.ipynb
+++ b/Untitled.ipynb
@@ -21,7 +21,7 @@
},
{
"cell_type": "code",
- "execution_count": 3,
+ "execution_count": 2,
"id": "aa37467f",
"metadata": {},
"outputs": [],
@@ -32,7 +32,7 @@
},
{
"cell_type": "code",
- "execution_count": 4,
+ "execution_count": 3,
"id": "af67d5ab-f313-4b9a-bc44-1c6494b3c2e6",
"metadata": {},
"outputs": [],
@@ -42,23 +42,23 @@
},
{
"cell_type": "code",
- "execution_count": 5,
+ "execution_count": 4,
"id": "fa18649a-45b7-47fe-bfea-8c1f2a3226af",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
- "[<matplotlib.lines.Line2D at 0x106d57c80>]"
+ "[<matplotlib.lines.Line2D at 0x107e43560>]"
]
},
- "execution_count": 5,
+ "execution_count": 4,
"metadata": {},
"output_type": "execute_result"
},
{
"data": {
- "image/png": "iVBORw0KGg<Escape>oAAAANSUhEUgAAAh8AAAGdCAYAAACyzRGfAAAAOnRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjEwLjEsIGh0dHBzOi8vbWF0cGxvdGxpYi5vcmcvc2/+5QAAAAlwSFlzAAAPYQAAD2EBqD+naQAAPT9JREFUeJzt3QlYVXX...,
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAAigAAAGdCAYAAAA44ojeAAAAOnRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjEwLjEsIGh0dHBzOi8vbWF0cGxvdGxpYi5vcmcvc2/+5QAAAAlwSFlzAAAPYQAAD2EBqD+naQAAOqpJREFUeJzt3Ql4lNXd/vE7e0gg...
"text/plain": [
"<Figure size 640x480 with 1 Axes>"
]
@@ -68,7 +68,7 @@
}
],
"source": [
- "plt.plot(x, x**2)"
+ "plt.plot(x, x**3)"
]
}
],Not only are these diffs impossible to read for an individual, they also make resolving merge conflicts very difficult.
Test with pytest
Because marimo notebooks are just Python files, they are interoperable with other tools for Python — including pytest. In contrast, there is no standard way to test code in Jupyter notebooks, which is part of the reason why so many traditional notebooks fall over from incorrectness.
Testing cells. Any cell named as test_* is automatically discoverable
and testable by pytest. The same goes for any cell that contains only test_
functions and Test classes.
Importantly, because cells are wrapped in functions, running pytest test_notebook.py
doesn’t execute the entire notebook — just its tests.
Example. Consider running pytest on the following code:
import marimo
__generated_with = "0.11.17"
app = marimo.App()
@app.cell
def _():
def inc(x):
return x + 1
return (inc,)
@app.cell
def test_fails(inc):
assert inc(3) == 5, "This test fails"
@app.cell
def test_sanity(inc):
assert inc(3) == 4, "This test passes"
@app.cell
def collection_of_tests(inc, pytest):
@pytest.mark.parametrize("input, expected", [(3, 4), (4, 5)])
def test_answer(x, y):
assert inc(x) == y, "These tests should pass."
@app.cell
def imports():
import pytest
return pytestThis prints:
============================= test session starts ==============================
platform linux -- Python 3.11.10, pytest-8.3.4, pluggy-1.5.0
rootdir: /notebooks
configfile: pyproject.toml
collected 4 items
test_notebook.py::test_fails FAILED [ 25%]
test_notebook.py::test_sanity PASSED [ 50%]
test_notebook.py::MarimoTestBlock_0::test_parameterized[3-4] PASSED [ 75%]
test_notebook.py::MarimoTestBlock_0::test_parameterized[4-5] PASSED [100%]
=================================== FAILURES ===================================
__________________________________ test_fails __________________________________
@app.cell
def test_fails(inc):
> assert inc(3) == 5, "This test fails"
E AssertionError: This test fails
E assert 4 == 5
E + where 4 = <function inc>(3)
test_notebook.py:17: AssertionError
=========================== short test summary info ============================
FAILED test_notebook.py::test_fails - AssertionError: This test fails
assert 4 == 5
+ where 4 = <function inc>(3)
========================= 1 failed, 3 passed in 0.65s ==========================Test with doctests
marimo also supports doctest
out of the box: just call doctest.testmod() in your notebook, in a cell that
references the functions you’d like to test.
This can be especially helpful when defining and documenting functions in marimo notebooks that will be used elsewhere.
Reuse functions and classes in other Python files
Coming soon, in version 0.12.0.
Our file format also makes it easy and natural to reuse functions and classes defined in your notebook; just import them like you would from a regular notebook file:
from my_notebook import my_function, my_classThis works for cells that have just a single function definition or class definition. Additionally, the functions and classes must have no other references other than imported modules or other symbols that you the notebook author define in a special setup cell (functions and classes can also refer to other top-level functions).
For example, the below notebook contains a setup cell that imports numpy, and
a cell that defines a function that uses numpy. Unlike other cells, the setup
cell’s body is at the top-level of the file (it’s not wrapped in a
function), so its variables are made available to the notebook’s functions.
import marimo
__generated_with = "0.11.17"
app = marimo.App()
with app.setup:
import numpy as np
@app.function
def my_function(x: np.ndarray):
return np.mean(x)You can define the setup cell by simply editing the notebook file in a text editor, or through the marimo editor.
Reuse cells and notebooks in other notebooks
Cells. Named cells can be used in other notebooks:
- Import a cell with
from my_notebook import my_cell - Run it with
defs, output = my_cell.run(), which runs the cell and its ancestors.
Here, defs is a dictionary containing the variables the cell defines, and output
the value of the cell’s last expression (i.e., its visual output).
By default, running a cell in this way will also run its ancestors. The run
method can be parametrized to override the values of its references and
prevent ancestor execution. (This API was inspired by Observable notebooks.)
See our docs for an
example.
Notebooks. Entire notebooks can be embedded in other notebooks:
from my_notebook import appresult = await app.embed()
result.outputThis lets you reuse the user interface of a marimo notebook as a component (since marimo makes it easy for notebooks to be rendered as interactive web apps). Our docs include a usage example.
Run as Python scripts
Every marimo notebook can be run as a script;
python my_notebook.pyThis runs the notebook cells in a topologically sorted order. You can also
pass command-line arguments to your notebook, which can be read with the library
function marimo.cli_args():
python my_notebook.py -- -x=1Since marimo notebooks are just Python, you can also use argparse
to declare and parse arguments. And, since marimo does not support magic
commands (we don’t need
them),
your notebook is guaranteed to work as as script.
Script metadata for packaging and configuration
Thanks to PEP 723, there is now an agreed-upon Python specification for storing metadata in single-file Python scripts. This metadata is similar to a pyproject.toml and stored as a header comment, such as:
# /// script
# requires-python = ">=3.11"
# dependencies = [
# "requests<3",
# "rich",
# ]
# ///Because marimo notebooks are just Python files, we can use this spec to communicate metadata to other tools in the Python ecosystem.
Package requirements. For reproducibility, marimo users can document their
notebook’s dependencies in script metadata. When given a notebook with inline
dependencies, marimo uses uv to run it in
an isolated virtual environment. marimo can even automatically
maintain this
dependency list on the user’s behalf.
Configuration overrides. Users can use script metadata to easily override marimo configuration on a per-notebook basis.
Embed SQL and Markdown
Even though marimo notebooks are stored as pure Python, other languages can be used by embedding them in Python.
For example, marimo has native support for “SQL cells”, powered by DuckDB or other databases. Though the marimo editor renders these cells as SQL, under the hood they are represented as
@app.cell
def _():
_df = mo.sql(f"SELECT * FROM my_table")The marimo parser even statically analyzes SQL code to build a dataflow graph jointly across Python and SQL.
Markdown is embedded in marimo notebooks in a similar way:
mo.md(f"The result of your query is {mo.as_html(df)}")As you can see above, a benefit of embedding other languages in Python is that it enables users to interpolate Python values into SQL and Markdown at runtime.
Edit as plaintext files
As a final example, our plaintext format makes it easy to edit marimo notebooks in a text editor of your choice; marimo will pick up your changes and reflect them in the browser. The plaintext file format also means you can lint and format notebook files using your preferred tools.
While you don’t need to maintain the cell arguments and returns, doing so can help your IDE provide completions. We have changes queued up that will make this feel like a first-class experience.
Output storage
Our file format has tradeoffs — in particular, storing as a Python file means that notebook outputs are no longer serialized in the notebook file. We accommodate output persistence in the following ways:
- Notebook outputs are cached in the
__marimo__directory (similar to__pycache__); on notebook startup, these outputs are matched with notebook cells, letting you see where you left off. - Notebooks can be automatically snapshotted as IPython notebook files or HTML,
which are also saved to the
__marimo__subdirectory. - An opt-in caching mechanism lets you pick up from where you left off (a topic large enough for a whole other blog post).
- Lightweight notebooks can be opened in our WebAssembly playground using our bookmarklet.
It just works
We regularly get feedback from users telling us how much they appreciate marimo’s embrace of pure Python.
For example, one user at a large company told us how marimo’s Python-first design means his notebooks are, for the first time, actually reusable and reproducible software artifacts:
My colleagues used to ask me what I did to reach certain conclusions … I would just send them my Jupyter notebook, but rarely did it ever actually run properly without issue, and it was always a mystery what specific order I ran the cells in to get them to work. I would end up just redoing a lot of the analysis in pure Python to replicate what was done, which was so inefficient. marimo has definitely solved that issue.
Others tell us they came for marimo’s interactivity, but stayed for the ability
to run notebooks as scripts. Conversely, others tell us they came for
git-versioning, or for the tight integration with uv, and stayed for
reactive execution or rich dataframes. Here’s a quote from a user that
speaks to this:
I haven‘t touched Jupyter or Pandas for a while now and not regretting it. My basic data stack is now uv, polars, marimo. One of my favourite features is that the notebooks are pure Python files and integrate uv script headers to make them out-of-the-box executable.
More generally, when we ask our users why they keep using marimo, we hear quotes like this one:
Well it just works!
It just works.
While marimo was originally developed with input from Stanford scientists, it is now used by developers at dozens of companies across the world, including OpenAI, BlackRock, and Moderna; it is also used by researchers and educators at Berkeley, Stanford, NASA, CZI, and other institutions.
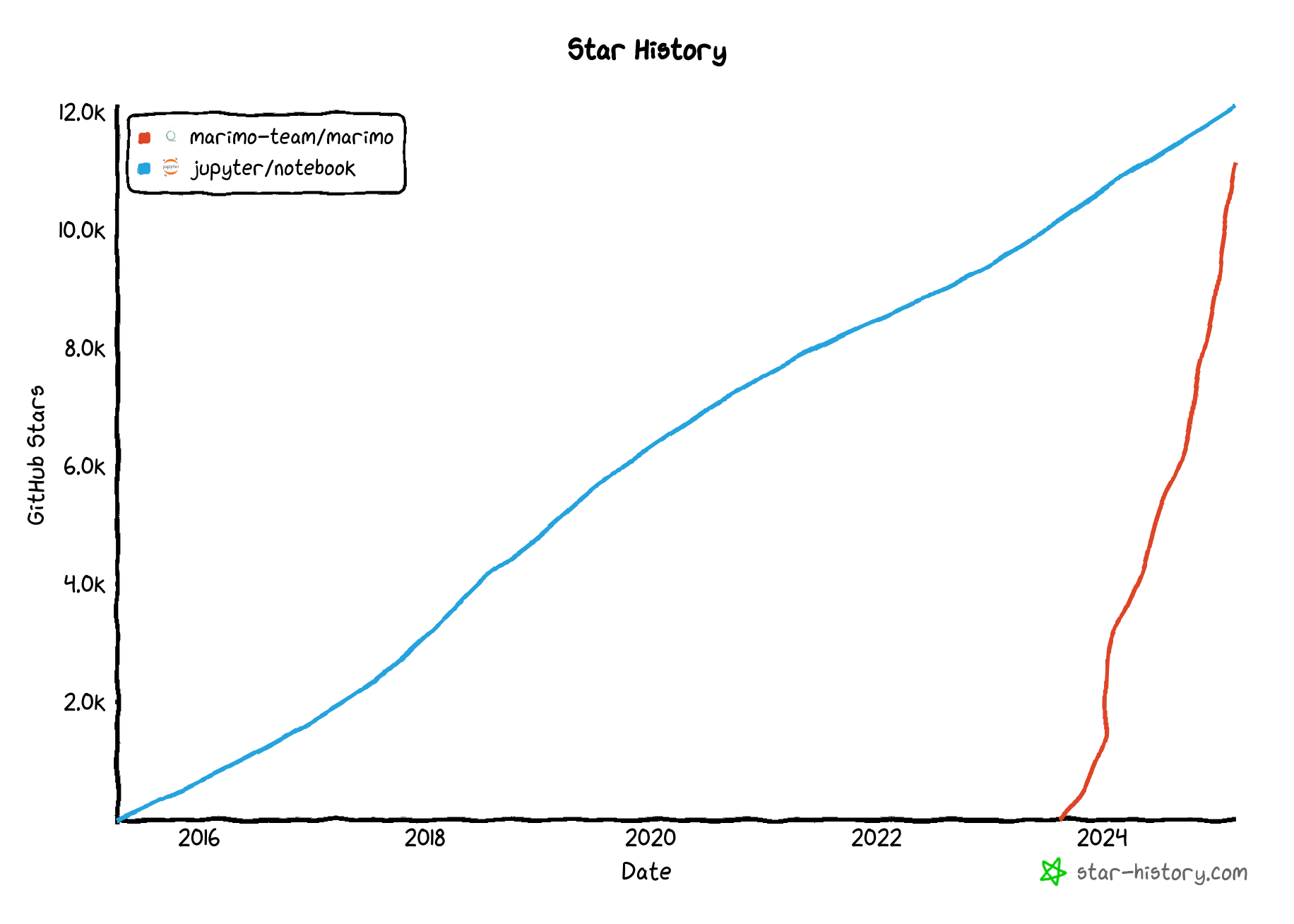
marimo is quickly establishing itself as a new standard for interactive computing. The marimo package is downloaded hundreds of thousands of times a month, and the marimo GitHub repository has over 11,000 stars, with over 100 contributors.
Join the marimo community
If you're interested in helping shape marimo's future, here are some ways you can get involved:



