Introducing marimo pair
A canvas where agents and developers collaborate on research and data work; structured working memory and a reactive Python runtime for agents.
Today, we’re releasing marimo pair, a brand new way for agents and developers to collaborate on computational research and data work, and a powerful new computational environment for agents.
Coding agents interact with programs in a loop that involves reading code, editing files, and running tests. While this works well for software engineering, it isn’t a good fit for research and data work, which is more exploratory. Researchers prefer to incrementally execute code, interrogating data held in memory to decide what action to take next — that’s why nearly all researchers start their work in interactive programming environments like notebooks. Agents haven’t had access to the intermdiate variables in these environments, limiting their usefulness. That changes today, with marimo pair.
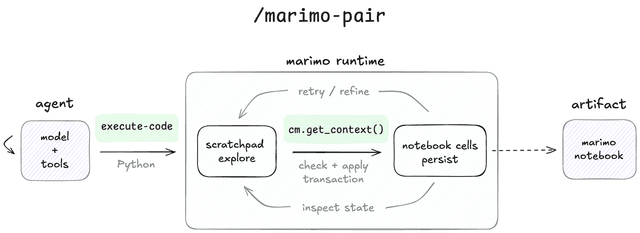
marimo pair is a skill that drops agents inside a running marimo notebook session, giving them full control over the notebook. Agents can do anything humans do in the notebook and more. This makes it possible for humans and agents to collaborate on research and data work, with the marimo notebook serving as a shared canvas; it also lets agents use marimo as a specialized reactive REPL that eliminates hidden state and guarantees the construction of a reproducible Python program.
Quickstart
marimo pair is implemented as an agent skill. Install it with:
npx skills add marimo-team/marimo-pairThen drop your agent of choice into a notebook with:
/marimo-pair pair with me on my_notebook.pyUse cases
Here are just a few use cases that we’ve experimented with:
Exploratory data analysis. marimo pair makes it easy to dive deeply into large datasets together with agents. Because agents can execute code in the kernel, they can inspect datasets, understand their structure, search for anomalies, visualize them, and more, with zero babysitting on your part. They can even help you sift through scatterplots of embedded data, manipulating visualizations on your behalf.
Data exploration
Recursive language models
Autoresearch. It is well known that autoresearch is most effective when guided by human steering, especially in the early stages of ideation. If you’re a researcher optimizing a metric, marimo pair lets you work with an agent to zero-in on experiments that you think will improve that metric. Then, let dozens of agents loose with variations on the experiments you identified.
Implement a paper. Give an agent a link to a paper, and have it generate a notebook for you that teaches you its core concepts, asking questions as it builds. We even have a skill for this.
Recursive language models. Attach models to the marimo kernel to extend their context windows with a reactive REPL that keeps them on track by eliminating hidden state and producing replayable Python programs. Stay tuned.
Data engineering. Have your agent join tables, query them, find insights, and build pipelines. Because marimo pair lets your agent read program memory, you never have to describe the schema of your data to your agent.
Software engineering. Finally, the marimo team uses marimo pair to find and fix bugs in marimo itself.
Implementation
The marimo pair agent skill. marimo pair is implemented as an agent skill. The agent can do anything a human can do with marimo and more.
The agent can obtain immediate feedback by running arbitrary code in an ephemeral scratchpad that contains the notebook’s variables in memory; this allows the agent to incrementally validate logic without making changes to the notebook source code. It can persist state by adding cells, deleting them, or installing packages (marimo records these actions in the associated notebook, which is just a Python file).
The agent does all this by running Python code in the marimo kernel. Under the hood — with just two bash scripts and supporting documentation — marimo pair teaches the agent how to discover and create marimo sessions, and how to execute code in the kernel using a semi-private interface we call code mode.
Code mode: an API for models. Code mode lets models treat marimo as a REPL that extends their context windows. But unlike traditional REPLs, the marimo “REPL” incrementally builds a reproducible Python program, because marimo notebooks are dataflow graphs with well-defined execution semantics.
As it uses code mode, the agent is kept on track by the same guardrails that marimo gives humans. These guardrails include the elimination of hidden state: run a cell and dependent cells are run automatically, delete a cell and its variables are scrubbed from memory.
Code mode is not a public, versioned API. It is an internal interface whose consumer is a model. The contract is not between two pieces of software; it is between a runtime and a model that can read docs and figure out what is in front of it. We are rapidly iterating on code mode, knowing that if we make changes from one version to the next, the models will adapt.
What’s next
marimo pair makes agents true participants in computational research and data work, while also providing a powerful code execution environment for models. We’re working on both these directions, and will have more updates to share soon.
In the meantime, we would love your feedback: try it out, open issues, and let us know how you’re using it.